Faculty: Rajeev Alur, Osbert Bastani, and Dinesh Jayaraman
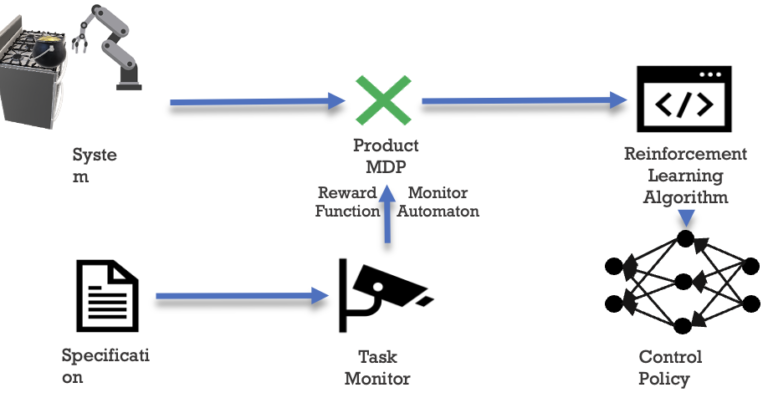
Problem: To synthesize control policies for robotic tasks using RL, user must specify rewards as numerical values associated with states. Such reward engineering requires expertise and is error prone.
Solution:Allow user to express intent using high-level logical specifications.